NTCIR-17に参加しました
12/13,12/14の2日間,NTCIR-17に一般参加しました.
NTCIRとは情報アクセス技術,特に評価方法や評価尺度の側面に焦点を当てて取り組むプロジェクトで,1年半に1度カンファレンスが開催されています.
ここ数年はコロナウイルス感染拡大の影響もあり,オンラインでの開催となっていましたが,約3年ぶりに対面での開催となりました.
基調講演やタスク参加者の発表を始めとして非常に興味深い発表が数多くあり,まさに最先端の研究に触れる良い場となりました.
私は聴講での参加という形でしたが,発表を聞いていて面白いと感じた技術・感想等をまとめたいと思い,本記事を記述することにしました.
NTCIR-17について
NTCIR-17は合計X個のタスクからなり,…です.
1. API Keyを取得する.
OpenAI API(公式ページ)から,頑張って取得しましょう.
英語で書かれているのでギョッとしますが,Google翻訳でなんとか乗り切ります.
2023年5月現在,無料では発行できないとかなんとか…
2. APIを叩くためのコードを書く.
実はChatGPTがあれば,自分でコードを書く必要さえありません.
ChatGPTに聞いても良いのですが,ChatGPTが正確なコードを出すのは当たり前感あるので,今回はBard(Googleの生成AI)に聞いてみましょう.
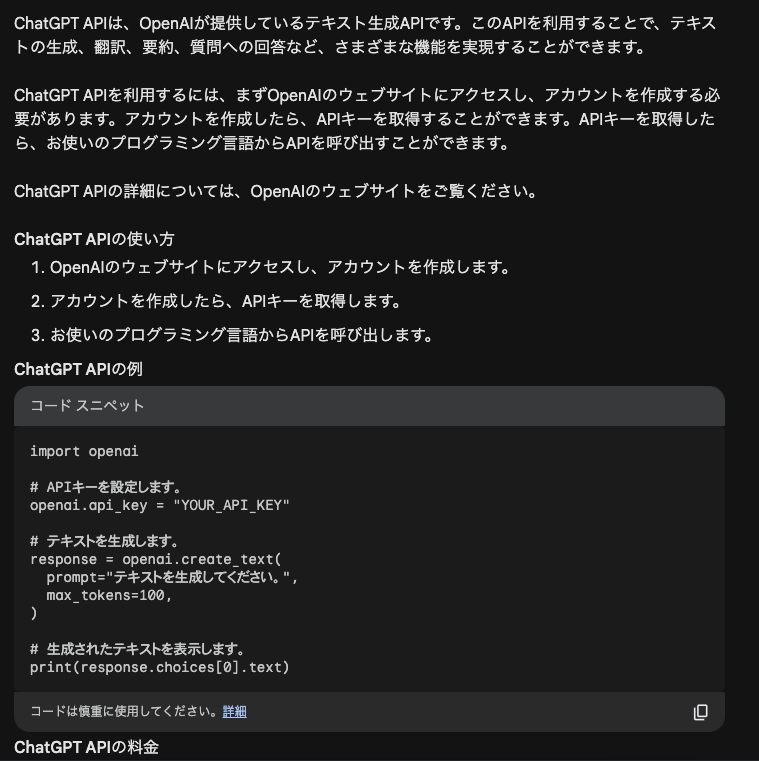
うーん…
大まかな流れはあっていますが,本当にこのコードで上手くいくのか?という感じがします.
何となく不安なので,ChatGPTにも聞いてみましょう.
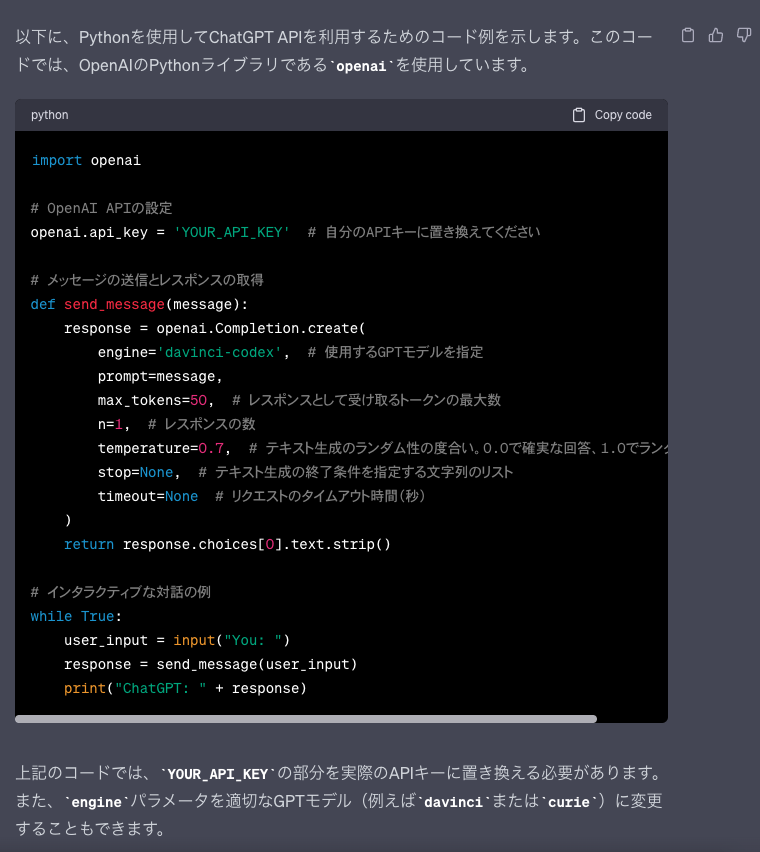
いやー,流石ですね.
感心を通り越して,感動するレベルです.
ということで,このコードを手元のマシンで実行してみましょう.
import openai
# OpenAI APIの設定
openai.api_key = 'YOUR_API_KEY' # 自分のAPIキーに置き換えてください
# メッセージの送信とレスポンスの取得
def send_message(message):
response = openai.Completion.create(
engine='davinci-codex', # 使用するGPTモデルを指定
prompt=message,
max_tokens=50, # レスポンスとして受け取るトークンの最大数
n=1, # レスポンスの数
temperature=0.7, # テキスト生成のランダム性の度合い。0.0で確実な回答、1.0でランダムな回答
stop=None, # テキスト生成の終了条件を指定する文字列のリスト
timeout=None # リクエストのタイムアウト時間(秒)
)
return response.choices[0].text.strip()
# インタラクティブな対話の例
while True:
user_input = input("You: ")
response = send_message(user_input)
print("ChatGPT: " + response)
上手くいくでしょうか?
私の環境で実行したところ,以下のエラーが返ってきました.
The model: `davinci-codex` does not exist
2023年5月現在,davinci-codexというモデルは存在していないんですね.
代わりに,’gpt-3.5-turbo’を使ってみましょう.
import openai
# OpenAI APIの設定
openai.api_key = OPEN_AI_API_KEY # 自分のAPIキーに置き換えてください
# メッセージの送信とレスポンスの取得
def send_message(message):
response = openai.ChatCompletion.create(
model='gpt-3.5-turbo', # 使用するGPTモデルを指定
messages = [
{'role': 'system', 'content': 'You are a helpful assistant.'},
{'role': 'user', 'content': message}])
last_message = response["choices"][0]["message"]
return last_message["content"]
# インタラクティブな対話の例
while True:
user_input = input("You: ")
response = send_message(user_input)
print("ChatGPT: " + response)
2023年5月現在では,上手く動作するコードになりました.